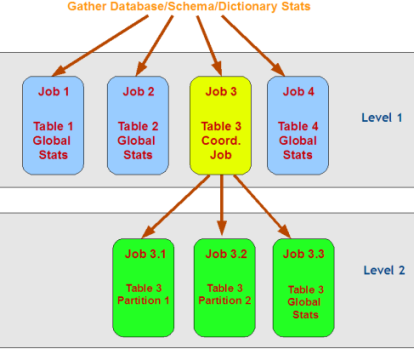
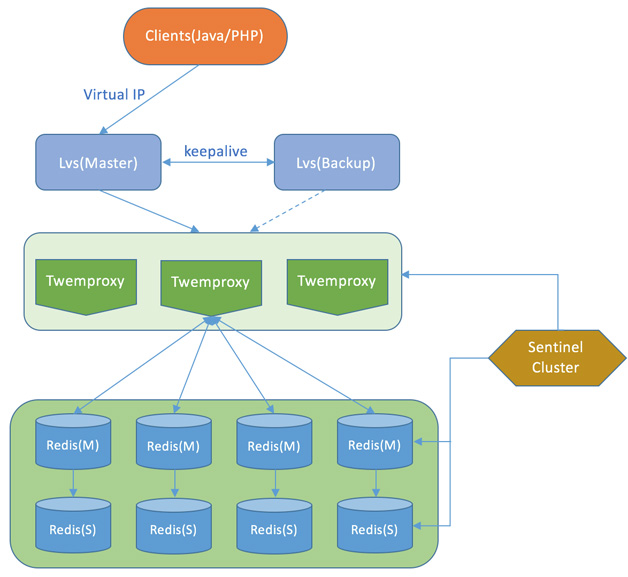
| NB |
Prob |
Bug |
Fixed |
Description |
| P |
IIII |
7272646 |
|
Linux-x86_64: ORA-27103 on startup when MEMORY_TARGET > 3g |
|
IIII |
18384537 |
11.2.0.4.6, 11.2.0.4.BP13, 12.1.0.2, 12.2.0.0 |
Process spin in opipls() / ORA-4030 for “kgh stack” memory |
|
IIII |
18148383 |
11.2.0.4.BP16, 12.1.0.1.5, 12.1.0.2, 12.2.0.0 |
AWR snapshots stopped , MMON hung with “EMON to process ntnfs” |
|
IIII |
17951233 |
11.2.0.4.4, 11.2.0.4.BP11, 12.1.0.2, 12.2.0.0 |
ORA-600 [kcblin_3] [103] after setting _pga_max_size > 2Gb |
|
IIII |
17867137 |
12.1.0.1.4, 12.1.0.2, 12.2.0.0 |
ORA-700 [Offload issue job timed out] on Exadata storage with fix of bug 16173738 present |
|
IIII |
17831758 |
12.1.0.2, 12.2.0.0 |
ORA-600 [kwqitnmphe:ltbagi] in Qnnn background process |
|
IIII |
17469624 |
11.2.0.4.BP15, 12.1.0.2, 12.2.0.0 |
ORA-600 [kcfis_finalize_cached_sessions_2] / ORA-600 [kcfis_update_recoverable_val_3] during session cleanup |
|
IIII |
17339455 |
12.1.0.2, 12.2.0.0 |
ORA-7445 [kkorminl] or similar can occur when running Automatic tuning tasks / DBMS_SQLTUNE Index Advisor |
|
IIII |
17306264 |
12.1.0.2, 12.2.0.0 |
Frequent ORA-1628 max # extents (32765) reached for rollback segment |
|
IIII |
17079301 |
11.2.0.4.BP14, 12.1.0.2, 12.2.0.0 |
ORA-6525 length mismatch from MMON job |
|
IIII |
17042658 |
11.2.0.4.4, 11.2.0.4.BP09, 12.1.0.1.3, 12.1.0.2, 12.2.0.0 |
ORA-600 [kewrsp_split_partition_2] during AWR purge |
|
IIII |
17037130 |
11.2.0.4.4, 11.2.0.4.BP10, 12.1.0.2, 12.2.0.0 |
Excess shared pool “PRTMV” memory use / ORA-4031 with partitioned tables |
|
IIII |
16989630 |
12.1.0.2, 12.2.0.0 |
Intermitent ORA-7445 [kglHandleParent] / [kglGetMutex] / [kglic0] |
|
IIII |
16667538 |
11.2.0.4.BP15, 12.1.0.2, 12.2.0.0 |
SGA memory corruption possible (single bit 0x1000 cleared) |
|
IIII |
16621589 |
12.1.0.2, 12.2.0.0 |
ORA-1426 “numeric overflow” from AUTO_SPACE_ADVISOR_JOB_PROC |
|
IIII |
16268425 |
11.2.0.4.3, 11.2.0.4.BP04, 12.1.0.2, 12.2.0.0 |
Memory corruption / ORA-7445 / ORA-600 gathering statistics in parallel for table with virtual column/s |
|
IIII |
16002686 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-7445 [kglbrk] or ORA-7445 [kxsSqlId] in shared server process |
|
IIII |
14764829 |
11.2.0.4.4, 11.2.0.4.BP11, 12.1.0.2, 12.2.0.0 |
ORA-600[kwqicgpc:cursta] can occur using AQ |
|
IIII |
14084247 |
11.2.0.3.BP24, 11.2.0.4.4, 11.2.0.4.BP07, 12.1.0.2, 12.2.0.0 |
ORA-1555 or ORA-12571 Failed AWR purge can lead to continued SYSAUX space use |
|
IIII |
13814203 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-600 [ktsapsblk-1] from SQL Tuning |
|
IIII |
16472780 |
11.2.0.4, 12.1.0.2 |
PGA memory leak ORA-600 [723] for “Fixed Uga” memory |
|
IIII |
15993436 |
12.1.0.2 |
Intermittent ORA-7445 [kokacau] errors |
|
IIII |
16477664 |
11.2.0.4.BP09, 12.1.0.1 |
ORA-600 [kokuxpout3] can occur querying some V$ views |
|
IIII |
16166364 |
12.1.0.1 |
ORA-600 [rworofprFastUnpackRowsets:oobp] or similar from Parallel Query |
|
IIII |
14843189 |
12.1.0.1 |
Select list pruning with subqueries / ORA-7445 [msqcol] |
|
IIII |
14602788 |
11.2.0.4.3, 11.2.0.4.BP07, 12.1.0.1 |
Q00* process spin when buffered messages spill |
|
IIII |
14275161 |
11.2.0.4.BP16, 12.1.0.1 |
ORA-600 [rwoirw: check ret val] on CTAS with predicate move around |
|
IIII |
14201252 |
11.2.0.4, 12.1.0.1 |
Stack corruption within kponPurgeUnreachLoc |
|
IIII |
14119856 |
11.2.0.4, 12.1.0.1 |
ORA-4030 occurs at 16gb of PGA even if it could grow much larger |
|
IIII |
14040124 |
11.2.0.4, 12.1.0.1 |
ORA-7445 [ktspsrch_reset] during commit on ASSM segment |
|
IIII |
14034426 |
11.2.0.3.BP25, 11.2.0.4.5, 11.2.0.4.BP09, 12.1.0.1 |
ORA-600 [kjbrfixres:stalew] in LMS in RAC |
|
IIII |
14024668 |
11.2.0.4, 12.1.0.1 |
ORA-7445 [ksuklms] from ‘alter system kill session (non-existent)’ |
|
IIII |
13914613 |
11.2.0.3.6, 11.2.0.3.BP12, 11.2.0.4, 12.1.0.1 |
Excessive time holding shared pool latch in kghfrunp with auto memory management |
|
IIII |
13872868 |
11.2.0.3.10, 11.2.0.3.BP23, 11.2.0.4, 12.1.0.1 |
ORA-600[keomnReadGlobalInfoFromStream:magic] from V$SQL_MONITOR |
|
IIII |
13863932 |
11.2.0.3.BP22, 11.2.0.4, 12.1.0.1 |
ORA-600[12259] using JDBC application with PL/SQL |
|
IIII |
13680405 |
11.2.0.3.6, 11.2.0.3.BP16, 11.2.0.4, 12.1.0.1 |
PGA consumption keeps growing in DIA0 process |
|
IIII |
13608792 |
11.2.0.3.BP16, 11.2.0.4, 12.1.0.1 |
ORA-600 [15713] from Ctrl-C/interrupt of PQ |
|
IIII |
12656350 |
11.2.0.4, 12.1.0.1 |
Small parse overhead with fix for bug 12534597 present |
|
IIII |
12537316 |
11.2.0.4, 12.1.0.1 |
Assorted ORA-600 / ORA-7445 for SQL with merged subquery |
|
IIII |
11837095 |
11.2.0.3.BP10, 11.2.0.4, 12.1.0.1 |
“time drift detected” appears intermittently in alert log |
| P |
IIII |
11801934 |
11.2.0.4, 12.1.0.1 |
AIX: Wrong page-in and page-out OS VM stats in V$OSSTAT on AIX |
|
IIII |
11769185 |
11.2.0.4, 12.1.0.1 |
ORA-600 / ORA-7445 from SQL performance Analyzer for SQL with UNION and fake binds |
|
IIII |
10110625 |
11.2.0.3.11, 11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
DBSNMP.BSLN_INTERNAL reports ORA-6502 running BSLN_MAINTAIN_STATS_JOB |
| P+ |
IIII |
10194190 |
11.2.0.4.BP09 |
Solaris: Process spin and/or ASM and DB crash if RAC instance up for > 248 days |
|
IIII |
14076523 |
11.2.0.2.9, 11.2.0.2.BP18, 11.2.0.3.4, 11.2.0.3.BP11, 11.2.0.4 |
ORA-600 [kgxRelease-bad-holder] can occur in rare cases |
|
IIII |
9137871 |
11.2.0.2 |
ORA-600 [15851] using function based index on DATE column |
|
IIII |
22243719 |
11.2.0.4.161018, 12.1.0.2.161018, 12.2.0.0 |
Several Internal Errors due to Shared Pool Memory Corruptions in 11.2.0.4 and later. Instance may Crash |
| * |
IIII |
22241601 |
12.2.0.0 |
ORA-600 [kdsgrp1] ORA-1555 / ORA-600 [ktbdchk1: bad dscn] due to Invalid Commit SCN in INDEX block |
| *P |
IIII |
21915719 |
12.1.0.2.160419, 12.2.0.0 |
12c Hang: LGWR waiting for ‘lgwr any worker group’ or ORA-600 [kcrfrgv_nextlwn_scn] ORA-600 [krr_process_read_error_2] on IBM AIX / HPIA |
|
IIII |
21749315 |
12.2.0.0 |
ORA-600 [keomnReadBindsFromStream:magic] |
|
IIII |
21373473 |
12.1.0.2.160719, 12.1.0.2.DBBP12, 12.2.0.0 |
Excess “ges resource dynamic” memory use / ORA-4031 / instance crash in RAC with many distributed transactions / XA |
|
IIII |
21286665 |
11.2.0.4.160419, 12.2.0.0 |
“Streams AQ: enqueue blocked on low memory” waits with fix 18828868 – superseded |
|
IIII |
21283337 |
12.2.0.0 |
ORA-600 [kghstack_underflow_internal_1] or similar if fix for bug 19052685 present |
|
IIII |
21260431 |
12.1.0.2.160419, 12.2.0.0 |
Excessive “ges resource dynamic” memory use in shared pool in RAC (ORA-4031) |
|
IIII |
20987661 |
12.2.0.0 |
QMON slave processes reporting ORA-600 [kwqitnmphe:ltbagi] |
| E |
IIII |
20907061 |
12.1.0.2.161018, 12.2.0.0 |
high number of executions for recursive call on col$ |
|
IIII |
20877664 |
12.1.0.2.160119, 12.2.0.0 |
SQL Plan Management Slow with High Shared Pool Allocations |
|
IIII |
20844426 |
12.1.0.2.161018, 12.2.0.0 |
ORA-600 [kkzdgdefq] from DBMS_REFRESH.refresh |
| D |
IIII |
20636003 |
12.2.0.0 |
Slow Parsing caused by Dynamic Sampling (DS_SRV) queries (side effects possible ORA-12751/ ORA-29771) |
|
IIII |
20547245 |
12.2.0.0 |
ORA-7445 [lxregsergop] from query using REGEXP on Exadata |
|
IIII |
20505778 |
12.2.0.0 |
Private memory corruption / ORA-7445 [kfuhRemove] / ORA-7445 [kghstack_underflow_internal] / ORA-600[17147] from DBA_TABLESPACE_USAGE_METRICS |
|
IIII |
20476175 |
11.2.0.4.BP20, 12.1.0.2.5, 12.1.0.2.DBBP08, 12.2.0.0 |
High VERSION_COUNT (in V$SQLAREA) for query with OPT_PARAM(‘_fix_control’) hint |
|
IIII |
20387265 |
12.1.0.2.4, 12.1.0.2.DBBP07, 12.2.0.0 |
ORA-600 [Cursor not typechecked] errors on cursor executed from PLSQL |
|
IIII |
20186278 |
11.2.0.4.GIPSU07, 12.1.0.2.GIPSU04, 12.2.0.0 |
crfclust.bdb Becomes Huge Size Due to Sudden Retention Change |
|
IIII |
19942889 |
12.2.0.0 |
ORA-600 [kpdbSwitchPreRestore: txn] from SQL autotune of a remote (dblink) query – duplicate of bug 19052685 – superseded |
|
IIII |
19689979 |
12.1.0.2.160119, 12.1.0.2.DBBP07, 12.2.0.0 |
ORA-8103 or ORA-600 [ktecgsc:kcbz_objdchk] or Wrong Results on PARTITION table after TRUNCATE in 11.2.0.4 or above |
|
IIII |
19621704 |
12.2.0.0 |
PGA memory leak / ORA-600 [723] with large allocations of “mbr node memory” when using Spatial |
|
IIII |
19614585 |
11.2.0.4.BP17, 12.1.0.2.DBBP03, 12.2.0.0 |
Wrong Results / ORA-600 [kksgaGetNoAlloc_Int0] / ORA-7445 / ORA-8103 / ORA-1555 from query on RAC ADG Physical Standby Database |
|
IIII |
19509982 |
12.1.0.2.DBBP02, 12.2.0.0 |
Disable raising of ORA-1792 by default |
|
IIII |
19475971 |
12.2.0.0 |
ORA-600 [17285] from PLSQL packages |
|
IIII |
19450314 |
12.1.0.2.160419, 12.2.0.0 |
Unnecessary compiled PL/SQL invalidations in 12c |
|
IIII |
19366669 |
12.2.0.0 |
CRS-8503: oracle clusterware osysmond process experienced fatal signal or exception 11 – superseded |
|
IIII |
18899974 |
12.1.0.2.161018, 12.2.0.0 |
ORA-600 [kcbgtcr_13] on ADG for SPACE metadata blocks and UNDO blocks |
|
IIII |
18841764 |
12.2.0.0 |
Network related error like ORA-12592 or ORA-3137 or ORA-3106 may be signaled |
|
IIII |
18828868 |
11.2.0.4.5, 11.2.0.4.BP12, 12.1.0.2, 12.2.0.0 |
Too Many Qxxx Processes Maxing Out the Number of Processes with fix for bug 14602788 present |
|
IIII |
18758878 |
12.2.0.0 |
Automatic SQL tuning advisor fails with ORA-7445 [apaneg] |
| * |
IIII |
18607546 |
11.2.0.4.6, 11.2.0.4.BP16, 12.1.0.2.3, 12.1.0.2.DBBP06, 12.2.0.0 |
ORA-600 [kdblkcheckerror]..[6266] corruption with self-referenced chained row. ORA-600 [kdsgrp1] / Wrong Results / ORA-8102 |
|
IIII |
18536720 |
12.1.0.2, 12.2.0.0 |
ORA-600 [kwqitnmphe:ltbagi] processing History IOT in AQ |
|
IIII |
18280813 |
11.2.0.4.4, 11.2.0.4.BP10, 12.1.0.2, 12.2.0.0 |
Process hangs in ‘gc current request’ in RAC |
|
IIII |
18199537 |
11.2.0.4.4, 11.2.0.4.BP10, 12.1.0.2, 12.2.0.0 |
RAC database becomes almost hung when large amount of row cache are used in shared pool |
|
IIII |
18189036 |
11.2.0.4.5, 11.2.0.4.BP14, 12.1.0.2, 12.2.0.0 |
ORA-600 [qkaffsindex3] from SQL Tuning task / advisor |
|
IIII |
17890099 |
12.1.0.2.160119, 12.1.0.2.DBBP07, 12.2.0.0 |
Wrong cardinality estimation for “is NULL” predicate on a remote table |
|
IIII |
17722075 |
12.1.0.2.160719, 12.2.0.0 |
ORA-7445 [kkcnrli] in Qnnn process during ALTER DATABASE OPEN |
|
IIII |
17551261 |
12.1.0.2.DBBP12, 12.2.0.0 |
ORA-942 / ORA-904 “from$_subquery$_###”.<column_name> with query rewrite |
|
IIII |
17365043 |
12.1.0.2.5, 12.1.0.2.DBBP10, 12.2.0.0 |
Session hangs on “Streams AQ: enqueue blocked on low memory” |
|
IIII |
17274537 |
11.2.0.4.5, 11.2.0.4.BP13, 12.1.0.2.3, 12.1.0.2.DBBP05, 12.2.0.0 |
ASM disk group force dismounted due to slow I/Os |
|
IIII |
17220460 |
12.1.0.2, 12.2.0.0 |
parallel query hangs with ‘PX Deq: Execute Reply’ |
| D |
IIII |
17018214 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-600 [krdrsb_end_qscn_2] ORA-4021 in Active Dataguard Standby Database with fix for bug 16717701 present – Instance may crash |
|
IIII |
16817656 |
12.2.0.0 |
ORA-7445[_int_malloc] on shared server process / IO failures on ASM leading to unnecessary Disk Offline in Exadata |
|
IIII |
16756406 |
12.2.0.0 |
ORA-600 [kpp_concatq:2] or hang when NCHAR/NVARCHAR2 AL16UTF16 characters are included in a SQL statement |
| D |
IIII |
16717701 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
Active Dataguard Hangs waiting for library cache lock on DBINSTANCE namespace with possible deadlock – Superseded |
|
IIII |
16504613 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-600[12337] from SQL with predicate of the form “NVL() [not] IN (inlist)” |
|
IIII |
15883525 |
11.2.0.3.9, 11.2.0.3.BP22, 11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-600 [kcbo_switch_cq_1] can occur causing an instance crash |
|
IIII |
14572561 |
11.2.0.4, 12.1.0.2, 12.2.0.0 |
ORA-7445 [pevm_SUBSTR] crash on packages with constants |
|
IIII |
13542050 |
12.1.0.2.160419, 12.2.0.0 |
A mutex related hang with holder around 65534 (0xfffe) – superseded |
|
IIII |
24316947 |
11.2.0.4.161018, 12.1.0.2.161018 |
ORA-07445 and ORA-00600 after applying 11.2.0.4/12.1.0.1/12.1.0.2 April DB PSU or DB Bundle Patch |
|
IIII |
19730508 |
11.2.0.4.5, 11.2.0.4.BP14, 12.1.0.2.3, 12.1.0.2.DBBP05 |
Orphan subscribers / ORA-600 [kwqdlprochstentry:ltbagi] on SYS$SERVICE_METRICS_TAB in RAC with fix of bug 14054676 present |
|
IIII |
17437634 |
11.2.0.3.9, 11.2.0.3.BP22, 11.2.0.4.2, 11.2.0.4.BP03, 12.1.0.1.3, 12.1.0.2 |
ORA-1578 or ORA-600 [6856] transient in-memory corruption on TEMP segment during transaction recovery / ROLLBACK (eg: after Ctrl-C) – superseded |
|
IIII |
17325413 |
11.2.0.3.BP23, 11.2.0.4.2, 11.2.0.4.BP04, 12.1.0.1.3, 12.1.0.2 |
Drop column with DEFAULT value and NOT NULL definition ends up with Dropped Column Data still on Disk leading to Corruption |
|
IIII |
18973907 |
11.2.0.4.4, 11.2.0.4.BP11, 12.1.0.1.5, 12.1.0.2 |
Memory corruption / various ORA-600/ORA-7445 using database links between 11.2.0.4/12.1.0.1 and earlier versions – superseded |
|
IIII |
12578873 |
11.2.0.4.BP15, 12.1.0.2 |
ORA-7445 [opiaba] when using more than 65535 bind variables |
| P |
IIII |
20675347 |
12.1.0.1 |
AIX: ORA-7445 [kghstack_overflow_internal] or ORA-600 [kghstack_underflow_internal_2] in 11.2.0.4 on IBM AIX |
|
IIII |
18235390 |
11.2.0.4.5, 11.2.0.4.BP14, 12.1.0.1 |
ORA-600 [kghstack_underflow_internal_3] … [kttets_cb – autoextfiles_kttetsrow] after applying patch 17897511 |
|
IIII |
17897511 |
12.1.0.1 |
ORA-1000 from query on DBA_TABLESPACE_USAGE_METRICS after upgrade to 11.2.0.4 – superseded |
|
IIII |
17586955 |
11.2.0.4.4, 11.2.0.4.BP11, 12.1.0.1 |
ORA-600 [ktspfmdb:objdchk_kcbnew_3] in RAC |
|
IIII |
17501296 |
11.2.0.4.BP09, 12.1.0.1 |
ORA-604 / PLS-306 attempting to delete rows from table with Text index after upgrade to 11.2.0.4 |
|
IIII |
16392079 |
11.2.0.4, 12.1.0.1 |
Sessions hang waiting for ‘resmgr:cpu quantum’ with Resource Manager |
|
IIII |
15881004 |
11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
Excessive SGA memory usage with Extended Cursor Sharing |
|
IIII |
14791477 |
11.2.0.3.8, 11.2.0.3.BP17, 11.2.0.4, 12.1.0.1 |
Instance eviction in RAC due to lock element shortage (Pseudo Reconfiguration reason 3) |
|
IIII |
14657740 |
11.2.0.3.11, 11.2.0.3.BP24, 11.2.0.4.4, 11.2.0.4.BP09, 12.1.0.1 |
ORA-600 [510] … [cache buffers chains] |
|
IIII |
14601231 |
11.2.0.3.BP16, 11.2.0.4, 12.1.0.1 |
ORA-7445 [kpughndlarr] / assorted ORA-600 |
|
IIII |
14588746 |
11.2.0.3.11, 11.2.0.3.BP23, 11.2.0.4, 12.1.0.1 |
ORA-600 [kjbmprlst:shadow] in LMS in RAC – crashes the instance |
|
IIII |
14489591 |
11.2.0.3.11, 11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
ORA-3137 [3149] on server due to bad bind attempt in client |
|
IIII |
14409183 |
11.2.0.3.4, 11.2.0.3.BP10, 11.2.0.4, 12.1.0.1 |
ORA-600 [kjblpkeydrmqscchk:pkey] or similar / session hangs on “gc buffer busy acquire” |
|
IIII |
14373728 |
11.2.0.4, 12.1.0.1 |
Old statistics not purged from SYSAUX tablespace |
|
IIII |
14192178 |
11.2.0.4, 12.1.0.1 |
EXPDP of partitioned table can be slow |
|
IIII |
14091984 |
11.2.0.4, 12.1.0.1 |
dump on kkoatsamppred |
| P |
IIII |
13940331 |
11.2.0.4, 12.1.0.1 |
AIX: OCSSD threads are not set to the correct priority |
|
IIII |
13931044 |
11.2.0.3.11, 11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
ORA-600 [13009] / ORA-600 [13030] with Nested Loop Batching |
|
IIII |
13869978 |
11.2.0.3.GIPSU04, 11.2.0.4, 12.1.0.1 |
OCSSD reports that the voting file is offline without reporting the reason |
|
IIII |
13860201 |
11.2.0.3.6, 11.2.0.3.BP12, 11.2.0.4, 12.1.0.1 |
Dump on kkspbd0 |
|
IIII |
13840704 |
11.2.0.3.11, 11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
ORA-12012 / ORA-6502 from Segment Advisor (DBMS_SPACE/DBMS_ADVISOR) for LOB segments |
|
IIII |
13737746 |
11.2.0.2.8, 11.2.0.2.BP16, 11.2.0.3.4, 11.2.0.3.BP05, 11.2.0.4, 12.1.0.1 |
Recovery fails with ORA-600 [krr_assemble_cv_12] or ORA-600[krr_assemble_cv_3] |
|
IIII |
13718279 |
11.2.0.3.4, 11.2.0.3.BP10, 11.2.0.4, 12.1.0.1 |
DB instance terminated due to ORA-29770 in RAC |
|
IIII |
13616375 |
11.2.0.2.11, 11.2.0.2.BP21, 11.2.0.3.6, 11.2.0.3.BP15, 11.2.0.4, 12.1.0.1 |
ORA-600 [qkaffsindex5] on a query with ORDER BY DESC and functional index on DESC column from SQL tuning index advisor job |
|
IIII |
13583663 |
11.2.0.4, 12.1.0.1 |
ORA-7445[opipls] from EXECUTE IMMEDIATE in PLSQL – superseded |
|
IIII |
13555112 |
11.2.0.4, 12.1.0.1 |
ORA-600 [kkopmCheckSmbUpdate:2] using plan baseline |
| + |
IIII |
13550185 |
11.2.0.2.9, 11.2.0.2.BP17, 11.2.0.3.4, 11.2.0.3.BP06, 11.2.0.4, 12.1.0.1 |
Hang / SGA memory corruption / ORA-7445 [kglic0] when using multiple shared pool subpools – superseded |
|
IIII |
13527323 |
11.2.0.3.3, 11.2.0.3.BP07, 11.2.0.4, 12.1.0.1 |
ORA-6502 generating HTML AWR report using awrrpt.sql in Multibyte characterset database |
|
IIII |
13493847 |
11.2.0.3.7, 11.2.0.3.BP14, 11.2.0.4, 12.1.0.1 |
ORA-600 [15709] can occur with Parallel Query |
|
IIII |
13477790 |
11.2.0.3.10, 11.2.0.3.BP04, 11.2.0.4, 12.1.0.1 |
ORA-7445 [kghalo] / memory errors / ORA-4030 from XMLForest / XMLElement |
|
IIII |
13464002 |
11.2.0.2.BP16, 11.2.0.3.4, 11.2.0.3.BP06, 11.2.0.4, 12.1.0.1 |
ORA-600 [kcbchg1_12] or ORA-600 [kdifind:kcbget_24] |
|
IIII |
13463131 |
11.2.0.3.BP23, 11.2.0.4, 12.1.0.1 |
Dump (kgghash) from bind peeking |
|
IIII |
13456573 |
11.2.0.3.BP23, 11.2.0.4, 12.1.0.1 |
Many child cursors / ORA-4031 with large allocation in KGLH0 using extended cursor sharing |
|
IIII |
13397104 |
11.2.0.3.4, 11.2.0.3.BP09, 12.1.0.1 |
Instance crash with ORA-600 [kjblpkeydrmqscchk:pkey] or similar – superseded |
|
IIII |
13257247 |
10.2.0.5.7, 11.2.0.2.6, 11.2.0.2.BP15, 11.2.0.3.4, 11.2.0.3.BP04, 11.2.0.4, 12.1.0.1 |
AWR Snapshot collection hangs due to slow inserts into WRH$_TEMPSTATXS. |
|
IIII |
13250244 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3.4, 11.2.0.3.BP10, 11.2.0.4, 12.1.0.1 |
Shared pool leak of “KGLHD” memory when using multiple subpools |
|
IIII |
13099577 |
11.2.0.2.7, 11.2.0.2.BP16, 11.2.0.3.4, 11.2.0.3.BP05, 11.2.0.4, 12.1.0.1 |
ora-12801 and ORA-1460 with parallel query |
|
IIII |
13072654 |
11.2.0.3.8, 11.2.0.3.BP21, 11.2.0.4, 12.1.0.1 |
Unnecessary ORA-4031 for “large pool”,”PX msg pool” from PQ slaves |
|
IIII |
13000553 |
11.2.0.3.BP11, 11.2.0.4, 12.1.0.1 |
RMAN backup fails with RMAN-20999 error at standby database |
|
IIII |
12971242 |
11.2.0.4, 12.1.0.1 |
dumps occurs around kpofcr with STAR transformation |
|
IIII |
12919564 |
11.2.0.3.2, 11.2.0.3.BP04, 11.2.0.4, 12.1.0.1 |
ORA-600 [ktbesc_plugged] executing SQL against a Plugged in (transported) tablespace |
|
IIII |
12899768 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3.8, 11.2.0.3.BP11, 11.2.0.4, 12.1.0.1 |
Processed messages remain in Queue causing space issues |
|
IIII |
12880299 |
10.2.0.4.13, 10.2.0.5.8, 11.1.0.7.12, 11.2.0.2.7, 11.2.0.2.BP17, 11.2.0.3.3, 11.2.0.3.BP24, 11.2.0.4, 12.1.0.1 |
TCP handlers block if listener registration is restricted to IPC with COST |
|
IIII |
12865902 |
11.2.0.2.BP13, 11.2.0.3.8, 11.2.0.3.BP03, 11.2.0.4, 12.1.0.1 |
NOWAIT lock requests could hang (like Parallel Queries may hang “enq: TS – contention”) in RAC |
|
IIII |
12848798 |
11.2.0.2.9, 11.2.0.2.BP19, 11.2.0.3.BP13, 11.2.0.4, 12.1.0.1 |
OERI:kcbgtcr_13 on active dataguard |
|
IIII |
12834800 |
11.2.0.4, 12.1.0.1 |
ORA-7445 [qkxrPXformUnm] from SQL with positional ORDER BY or GROUP BY and function based index |
|
IIII |
12834027 |
11.2.0.2.8, 11.2.0.2.BP13, 11.2.0.3.1, 11.2.0.3.BP02, 11.2.0.4, 12.1.0.1 |
ORA-600 [kjbmprlst:shadow] / ORA-600 [kjbrasr:pkey] with RAC read mostly locking |
|
IIII |
12815057 |
11.2.0.3.8, 11.2.0.3.BP21, 11.2.0.4, 12.1.0.1 |
ORA-600/ORA-7445/ UGA memory corruptions using PLSQL callouts (such as SYS_CONTEXT) |
|
IIII |
12794305 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3.4, 11.2.0.3.BP09, 11.2.0.4, 12.1.0.1 |
ORA-600 [krsr_pic_complete.8] on standby database |
|
IIII |
12747437 |
11.2.0.3.8, 11.2.0.3.BP21, 11.2.0.4, 12.1.0.1 |
ORA-600 [ktspfmdb:objdchk_kcbnew_3] after purging single consumer queue table |
|
IIII |
12738119 |
11.2.0.3.BP22, 11.2.0.4, 12.1.0.1 |
RAC slow / repeat diagnostic dumps |
|
IIII |
12714511 |
11.2.0.4, 12.1.0.1 |
ORA-600 [17114] / memory corruption optimizing ANSI queries with FIRST_ROWS(K) |
|
IIII |
12683462 |
11.2.0.4, 12.1.0.1 |
Internal Errors / Wrong results from “PX SEND RANGE” |
|
IIII |
12680491 |
11.2.0.2.GIPSU04, 11.2.0.3.GIPSU03, 11.2.0.4, 12.1.0.1 |
Intermittent hiccup in network CHECK action can fail over vip, bring listener offline briefly |
|
IIII |
12672969 |
11.2.0.1.BP12, 11.2.0.2.BP12, 11.2.0.3.BP01, 11.2.0.4, 12.1.0.1 |
Assorted Dumps with aggregate expression in ORDER BY |
|
IIII |
12637294 |
11.2.0.3.BP11, 11.2.0.4, 12.1.0.1 |
Deadlock of PS and BF locks during parallel query operations |
|
IIII |
12552578 |
11.2.0.4, 12.1.0.1 |
ORA-1790 / ORA-600 [kkqtsetop.1] / ORA-1789 during SET operation query with redundant WHERE conditions |
| E |
IIII |
12534597 |
11.2.0.4, 12.1.0.1 |
Bind Peeking is disabled for remote queries |
|
IIII |
12531263 |
11.1.0.7.10, 11.2.0.2.5, 11.2.0.2.BP13, 11.2.0.2.GIPSU05, 11.2.0.3, 12.1.0.1 |
ORA-4020 on object $BUILD$.{Hexadecimal Number} |
|
IIII |
12340939 |
11.2.0.2.4, 11.2.0.2.BP10, 11.2.0.3, 12.1.0.1 |
ORA-7445 [kglic0] can occur capturing cursor stats for V$SQLSTATS |
|
IIII |
12312133 |
11.2.0.2.BP17, 11.2.0.3.8, 11.2.0.3.BP09, 11.2.0.4, 12.1.0.1 |
Standby DB crashes with ORA-600 [krcccb_busy] /Ora-00600 [krccckp_scn] with block change tracking |
|
IIII |
11902008 |
11.2.0.4, 12.1.0.1 |
SMON may crash with ORA-600 [kcbgcur_3] or ORA-600 [kcbnew_3] during Transaction recovery |
|
IIII |
11872103 |
11.2.0.2.7, 11.2.0.2.BP16, 11.2.0.3, 12.1.0.1 |
RMAN RESYNC CATALOG very slow / V$RMAN_STATUS incorrectly shows RUNNING |
| E |
IIII |
11869207 |
12.1.0.1 |
Improvements to archived statistics purging / SYSAUX tablespace grows – superseded |
|
IIII |
11744544 |
12.1.0.1 |
Set newname for database does not apply to block change tracking file |
| + |
IIII |
11666959 |
11.2.0.3, 12.1.0.1 |
ORA-7445 / LPX-200 / wrong results etc.. from new XML parser |
|
IIII |
11068682 |
11.2.0.4, 12.1.0.1 |
ORA-7445 [ph2csql_analyze] in active dataguard – superseded |
| E |
IIII |
10411618 |
11.1.0.7.9, 11.2.0.1.BP12, 11.2.0.2.2, 11.2.0.2.BP06, 11.2.0.3, 12.1.0.1 |
Enhancement to add different “Mutex” wait schemes |
|
IIII |
10314054 |
12.1.0.1 |
ORA-600 [13001] or similar from DELETE/UPDATE/MERGE SQL with non-deterministic WHERE clause |
|
IIII |
10279045 |
11.2.0.3, 12.1.0.1 |
Slow Statistics purging (SYSAUX grows) |
| + |
IIII |
10259620 |
11.2.0.2.BP12, 11.2.0.3, 12.1.0.1 |
Wrong results / ORA-7445 with DESC indexes and OR expansion |
|
IIII |
10237773 |
11.2.0.2.4, 11.2.0.2.BP12, 11.2.0.3, 12.1.0.1 |
ORA-600 [kcbz_check_objd_typ] / ORA-600 [ktecgsc:kcbz_objdchk] |
| E |
IIII |
10220118 |
11.2.0.2.BP02, 11.2.0.3, 12.1.0.1 |
Print warning to alert log when system is swapping |
|
IIII |
10204505 |
11.2.0.3, 12.1.0.1 |
SGA autotune can cause row cache misses, library cache reloads and parsing |
| E |
IIII |
10187168 |
11.1.0.7.7, 11.2.0.1.BP12, 11.2.0.2.2, 11.2.0.2.BP06, 11.2.0.3, 12.1.0.1 |
Enhancement to obsolete parent cursors if VERSION_COUNT exceeds a threshold |
|
IIII |
10155684 |
11.2.0.3, 12.1.0.1 |
ORA-600 [17099] / dump after session migration using trusted callout |
|
IIII |
10089333 |
11.2.0.2.6, 11.2.0.2.BP15, 11.2.0.3, 12.1.0.1 |
“init_heap_kfsg” memory leaks in SGA of db instance using ASM |
|
IIII |
10082277 |
11.2.0.1.BP12, 11.2.0.2.3, 11.2.0.2.BP04, 11.2.0.3, 12.1.0.1 |
Excessive allocation in PCUR or KGLH0 heap of “kkscsAddChildNo” (ORA-4031) |
|
IIII |
10018789 |
11.2.0.1.BP07, 11.2.0.2.2, 11.2.0.2.BP01, 11.2.0.3, 12.1.0.1 |
Spin in kgllock / DB hang with high library cache lock waits on ADG |
|
IIII |
10013177 |
11.2.0.2.6, 11.2.0.2.BP16, 11.2.0.3, 12.1.0.1 |
Wrong Results (truncate values) / dumps and internal errors with Functional based indexes of expressions used in Aggregations |
|
IIII |
10010310 |
10.2.0.5.3, 11.2.0.3, 12.1.0.1 |
ORA-27300 / ORA-27302 killing a non existing session |
|
IIII |
9964177 |
11.2.0.3, 12.1.0.1 |
ORA-7445 in/under LpxFSMSaxSE parsing an XML file due to the fact that lpxfsm_getattr_name() evaluates a string incorrectly |
| * |
IIII |
9877980 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3, 12.1.0.1 |
ORA-7445[kkslMarkLiteralBinds] / Assorted Errors on 11.2.0.2 if cursor sharing is enabled – Affects RMAN |
| P |
IIII |
9871302 |
11.2.0.3, 12.1.0.1 |
Windows: Cannot make new connection to database on Windows platforms with TNS-12560 |
|
IIII |
9829397 |
11.2.0.2.5, 11.2.0.2.BP13, 11.2.0.2.GIPSU05, 11.2.0.3, 12.1.0.1 |
Excessive CPU and many “asynch descriptor resize” waits for SQL using Async IO |
|
IIII |
9795214 |
11.1.0.7.7, 11.2.0.1.BP12, 11.2.0.2.4, 11.2.0.2.BP08, 11.2.0.3, 12.1.0.1 |
Library Cache Memory Corruption / ORA-600 [17074] may result in Instance crash |
|
IIII |
9772888 |
10.2.0.5.2, 11.2.0.2, 12.1.0.1 |
Needless “WARNING:Could not lower the asynch I/O limit to .. for SQL direct I/O It is set to -1” messages |
|
IIII |
9746210 |
11.2.0.2.4, 11.2.0.2.BP12, 11.2.0.3, 12.1.0.1 |
ORA-7445 [qsmmixComputeClusteringFactor] from SQL tuning |
| E |
IIII |
9735536 |
11.2.0.4, 12.1.0.1 |
Enhancement request which allows ability to selectively remove slow clients from Emon Notification mechanism |
| + |
IIII |
9735237 |
10.2.0.5.5, 11.2.0.2.1, 11.2.0.2.BP02, 11.2.0.3, 12.1.0.1 |
Dump [under kxspoac] / ORA-1722 as SQL uses child with mismatched BIND metadata |
| P |
IIII |
9728806 |
11.2.0.2, 12.1.0.1 |
ORA-7445 [kggibr()+52] during recovery on IBM AIX POWER Systems |
|
IIII |
9727147 |
11.2.0.2.5, 11.2.0.2.BP13, 11.2.0.2.GIPSU05, 11.2.0.3, 12.1.0.1 |
ORA-7445 [qksvcProcessVirtualColumn] using SQL Tuning / Index advisor |
|
IIII |
9706792 |
11.2.0.3.6, 11.2.0.3.BP07, 11.2.0.4, 12.1.0.1 |
ORA-600 [kcrpdv_noent] during STARTUP in Crash Recovery with Parallelism |
|
IIII |
9703463 |
11.1.0.7.8, 11.2.0.1.BP12, 11.2.0.2, 12.1.0.1 |
ORA-3137 [12333] or ORA-600 [kpobav-1] When Using Bind Peeking – superceded |
|
IIII |
9689310 |
10.2.0.5.7, 11.1.0.7.7, 11.2.0.1.BP08, 11.2.0.2, 12.1.0.1 |
Excessive child cursors / high VERSION_COUNT / ORA-600 [17059] due to bind mismatch |
|
IIII |
9651350 |
11.2.0.2.2, 11.2.0.2.BP05, 11.2.0.3, 12.1.0.1 |
Large redo dump and ORA-308 might be raised due to ORA-8103 |
|
IIII |
9594372 |
11.2.0.2, 12.1.0.1 |
A dump can occur in (kokscold) |
| + |
IIII |
9577583 |
11.2.0.1.BP08, 11.2.0.2, 12.1.0.1 |
False ORA-942 or other errors when multiple schemas have identical object names |
|
IIII |
9478199 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3, 12.1.0.1 |
Memory corruption / ORA-600 from PLSQL anonymous blocks |
| + |
IIII |
9399991 |
11.1.0.7.5, 11.2.0.1.3, 11.2.0.1.BP04, 11.2.0.2, 12.1.0.1 |
Assorted Internal Errors and Dumps (mostly under kkpa*/kcb*) from SQL against partitioned tables |
|
IIII |
9395500 |
11.2.0.1.BP07, 11.2.0.2, 12.1.0.1 |
Dump [kupfuDecompress] importing large table from compressed DMP file |
|
IIII |
9390347 |
11.2.0.2, 12.1.0.1 |
ADR purge may dump (DIA-48457 [11]) |
|
IIII |
9373370 |
11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3, 12.1.0.1 |
The wrong cursor may be executed by JDBC thin following a query timeout / ORA-3137 [12333] |
|
IIII |
9316980 |
11.2.0.3, 12.1.0.1 |
ORA-600 [723] UGA leak of “KPON Callback A” memory in QMNC slave (Qnnn process) |
|
IIII |
9243912 |
11.2.0.2, 12.1.0.1 |
Additional diagnostics for ORA-3137 [12333] / OERI:12333 |
|
IIII |
9233544 |
11.2.0.2.9, 11.2.0.2.BP19, 11.2.0.3, 12.1.0.1 |
ORA-600 [15709] during parallel rollback |
|
IIII |
9073910 |
11.2.0.4, 12.1.0.1 |
Direct path creates bad functional index on LOB column |
|
IIII |
9067282 |
11.2.0.1.2, 11.2.0.1.BP01, 11.2.0.3, 12.1.0.1 |
ORA-600 [kksfbc-wrong-kkscsflgs] can occur |
|
IIII |
9066130 |
10.2.0.5, 11.1.0.7.2, 11.2.0.2, 12.1.0.1 |
OERI [kksfbc-wrong-kkscsflgs] / spin with multiple children |
|
IIII |
9061785 |
11.2.0.1.BP04, 11.2.0.2, 12.1.0.1 |
Assorted Dumps from JPPD on distributed query with UNION ALL or OUTER JOIN |
|
IIII |
9050716 |
11.2.0.1.BP12, 11.2.0.2, 12.1.0.1 |
Dumps on kkqstcrf with ANSI joins and Join Elimination |
| *D |
IIII |
8895202 |
11.2.0.2, 12.1.0.1 |
ORA-1555 / ORA-600 [ktbdchk1: bad dscn] ORA-600 [2663] in Physical Standby after switchover – superseded |
|
IIII |
8865718 |
10.2.0.5.3, 11.1.0.7.4, 11.2.0.1.2, 11.2.0.1.BP06, 11.2.0.2, 12.1.0.1 |
Recursive cursors for MV refresh not shared |
|
IIII |
8797501 |
11.2.0.2, 12.1.0.1 |
OERI [qksdsInitSample:2] from SQL Tuning |
|
IIII |
8771916 |
10.2.0.5.3, 11.1.0.7.6, 11.2.0.1.BP12, 11.2.0.2, 12.1.0.1 |
OERI [kdsgrp1] during CR read |
|
IIII |
8763922 |
11.1.0.7.5, 11.2.0.1.BP09, 11.2.0.2, 12.1.0.1 |
Dump (kgghash) from bind peeking for RAW data types |
|
IIII |
8730312 |
11.2.0.1.BP04, 11.2.0.2, 12.1.0.1 |
wrong Null ASH data may cause dumps and kew* messages in alert.log |
|
IIII |
8666117 |
10.2.0.5.5, 11.2.0.2, 12.1.0.1 |
High row cache latch contention in RAC |
|
IIII |
8553944 |
11.2.0.2, 12.1.0.1 |
SYSAUX tablespace grows |
|
IIII |
8547978 |
11.2.0.2.9, 11.2.0.2.BP19, 11.2.0.3.6, 11.2.0.3.BP13, 11.2.0.4, 12.1.0.1 |
Online redefinition corrupts dictionary / ORA-600[kqd-objerror$] from DROP USER |
|
IIII |
8496830 |
11.1.0.7.3, 11.2.0.1.1, 11.2.0.1.BP03, 11.2.0.2, 12.1.0.1 |
ORA-8176 while inserting into global temp table |
|
IIII |
8477973 |
11.2.0.2, 12.1.0.1 |
Multiple open DB links / ORA-2020 / distributed deadlock / ORA-600 possible using DB Links |
|
IIII |
8434467 |
11.2.0.2, 12.1.0.1 |
SubOptimal Execution Plan for queries over V$RMAN_BACKUP_JOB_DETAILS |
|
IIII |
8223165 |
11.2.0.1.BP11, 11.2.0.2.3, 11.2.0.2.BP07, 11.2.0.3, 12.1.0.1 |
ORA-600 [ktsxtffs2] During Startup When Using Temporary Tablespace Group |
|
IIII |
8211733 |
10.2.0.5.3, 11.1.0.7.8, 11.2.0.2, 12.1.0.1 |
Shared pool latch contention when shared pool is shrinking |
|
IIII |
5702977 |
11.2.0.4, 12.1.0.1 |
Wrong cardinality estimation for “is NULL” predicate on a remote table – withdrawn |
| P |
IIII |
13604285 |
11.2.0.4, 12.1.0.0 |
Solaris: ora.net1.network keeps failing on Solaris 11 |
| E |
IIII |
8857940 |
12.1.0.0 |
Enhancement to group durations to help reduce chance of ORA-4031 |
|
IIII |
14313519 |
11.2.0.4 |
ORA-7445 [ktspsrch_reset] / ORA-7445 [ktspsrch_cbk] can occur (11g fix for bug 14040124) |
|
IIII |
12979199 |
11.2.0.2.BP15, 11.2.0.3.BP03, 11.2.0.4 |
ORA-1466 querying a Global Temporary Table in a READ ONLY transaction |
|
IIII |
12633340 |
11.2.0.2.6, 11.2.0.2.BP13, 11.2.0.3 |
Heavy “library cache lock” and “library cache: mutex X” contention for a “$BUILD$.xx” lock |
|
IIII |
10378005 |
11.2.0.2.3, 11.2.0.2.BP08, 11.2.0.3 |
ORA-600 [kolrarfc: invalid lob type] from LOB garbage collection |
|
IIII |
8579188 |
10.2.0.5, 11.2.0.2 |
CATALOG BACKUPIECE introduces invalid DATE (ORA-1861 produced by RMAN) |
|
IIII |
3934729 |
10.1.0.5, 10.2.0.3, 11.2.0.2, 9.2.0.7 |
Random dumps (nstimexp) using DCD |
| P |
IIII |
10190759 |
PSEONLY |
AIX: Processes consuming additional memory due to “Work USLA Heap” |
|
IIII |
14508968 |
11.2.0.3.10, 11.2.0.3.BP12, 11.2.0.4, 12.1.0.1 |
ORA-600 [504] [ges process parent latch] during logon in RAC |
|
IIII |
13004894 |
11.2.0.3.BP02, 11.2.0.4, 12.1.0.1 |
Wrong results with SQL_TRACE or 10046 or STATISTICS_LEVEL=ALL / Slow Parse |
|
IIII |
14013094 |
11.2.0.3.BP10, 11.2.0.4 |
DBMS_STATS places statistics in the wrong index partition |
|
IIII |
17230530 |
11.2.0.3.8, 11.2.0.3.BP21, 11.2.0.4 |
ORA-600 [kkzqid2fro] after apply 11.2.0.3.7 DB PSU |
|
IIII |
6904068 |
|
High CPU usage when there are “cursor: pin S” waits |
|
IIII |
9593134 |
11.2.0.2 |
DNS or NIS mis-configuration can cause slow database connects |
|
IIII |
9267837 |
11.1.0.7.8, 11.2.0.2 |
Auto-SGA policy may see larger resizes than needed |
|
IIII |
9002336 |
11.2.0.1.BP05, 11.2.0.2 |
Assorted Dumps with DISTINCT & WITH clause |
|
IIII |
8554900 |
11.2.0.2 |
PMON can crash the instance with OERI [ksnwait:nsevwait] |
|
IIII |
8625762 |
11.1.0.7.3, 11.2.0.1 |
ORA-3137 [12333] due to bind data not read from wire |
| * |
IIII |
8199533 |
10.2.0.5, 11.2.0.1 |
NUMA enabled by default can cause high CPU / OERI |
|
IIII |
7686855 |
11.2.0.1 |
ORA-600[kjucnl(pmon):!dead] from PMON cleaning dead distributed transaction |
| * |
IIII |
7662491 |
10.2.0.4.2, 10.2.0.5, 11.1.0.7.4, 11.2.0.1 |
Array Update can corrupt a row. Errors OERI[kghstack_free1] or OERI[kddummy_blkchk][6110] |
| + |
IIII |
7653579 |
11.1.0.7.2, 11.2.0.1 |
IPC send timeout in RAC after only short period |
|
IIII |
7648406 |
10.2.0.5, 11.1.0.7.4, 11.2.0.1 |
Child cursors not shared for “table_…” cursors (that show as “SQL Text Not Available”) when NLS_LENGTH_SEMANTICS = CHAR |
|
IIII |
7643188 |
10.2.0.5, 11.1.0.7.2, 11.2.0.1 |
Invalid / corrupt AWR SQL statistics |
|
IIII |
7626014 |
11.1.0.7.5, 11.2.0.1 |
OERI[kksfbc-new-child-thresh-exceeded] can occur / unnecessary child cursors |
|
IIII |
7523755 |
10.2.0.5, 11.2.0.1 |
“WARNING:Oracle process running out of OS kernel I/O resources” messages |
|
IIII |
7411568 |
10.2.0.5, 11.2.0.1 |
ORA-600[kcbbpibr_waitall_2] can occur |
|
IIII |
7385253 |
10.2.0.4.1, 10.2.0.5, 11.1.0.7.3, 11.2.0.1 |
Slow Truncate / DBWR uses high CPU / CKPT blocks on RO enqueue |
|
IIII |
7312791 |
10.2.0.5, 11.2.0.1 |
Dump (kokacau) if AQ client aborts with an active TX for dequeued message |
|
IIII |
7291739 |
10.2.0.4.4, 10.2.0.5, 11.2.0.1 |
Contention with auto-tuned undo retention or high TUNED_UNDORETENTION |
|
IIII |
7189722 |
10.2.0.5, 11.2.0.1 |
Frequent grow/shrink SGA resize operations |
|
IIII |
7039896 |
10.2.0.4.1, 10.2.0.5, 11.2.0.1 |
Spin under kghquiesce_regular_extent holding shared pool latch with AMM |
|
IIII |
6960699 |
10.2.0.5, 11.1.0.7, 11.2.0.1 |
“latch: cache buffers chains” contention/ORA-481/kjfcdrmrfg: SYNC TIMEOUT/ OERI[kjbldrmrpst:!master] |
|
IIII |
6918493 |
11.2.0.1 |
Net DCD (sqlnet.expire_time>0) can cause OS level mutex hang, possible to get PMON failed to acquired latch |
|
IIII |
6851110 |
10.2.0.5, 11.1.0.7.1, 11.2.0.1 |
ASMB process memory leak |
|
IIII |
6471770 |
10.2.0.5, 11.1.0.7, 11.2.0.1 |
ora-32690/OERI [32695] [hash aggregation can’t be done] from Hash GROUP BY |
| D |
IIII |
6376915 |
10.2.0.4, 11.1.0.7, 11.2.0.1 |
HW enqueue contention for ASSM LOB segments |
|
IIII |
6196748 |
10.2.0.5, 11.1.0.7.3, 11.2.0.1 |
Dump in ksxpmprp() during logoff with multiple sessions in one process |
|
IIII |
6139856 |
10.2.0.5, 11.1.0.7, 11.2.0.1 |
Memory corruption in Net nsevrec leading to dump |
|
IIII |
6113783 |
11.2.0.1 |
Arch processes can hang indefinitely on network |
| C |
IIII |
6085625 |
10.2.0.4, 11.1.0.7, 11.2.0.1 |
Wrong child cursor may be executed which has mismatching bind information |
|
IIII |
6034072 |
11.2.0.1 |
ORA-7445 [kgxMutexHng] / ORA-600 [ksdhng_callcbk: bad session 1] from hang analysis |
| D |
IIII |
6795880 |
10.2.0.5, 11.1.0.7 |
Session spins / OERI after ‘kksfbc child completion’ wait – superceded |
|
IIII |
6122696 |
10.2.0.5 |
ORA-7445 [osnsgl] after ORA-3115 error |
|
IIII |
8449495 |
|
ORA-600 [17280] if client killed when fetching from pipelined PLSQL function |
|
IIII |
5939230 |
10.2.0.5, 11.1.0.6 |
Dump [kkeidc] / memory corruption from query over database link |
|
IIII |
5890966 |
10.2.0.4, 11.1.0.6 |
Intermittent ORA-6502 with package level associative array |
| + |
IIII |
5868257 |
10.2.0.4.1, 10.2.0.5, 11.1.0.6 |
Dump / memory corruption from DMLs |
|
IIII |
5736850 |
10.2.0.4, 11.1.0.6 |
SGA corruption / crash from PQO bloom filter |
|
IIII |
5655419 |
11.1.0.6 |
Distributed transaction hits ORA-600:[1265] or ORA-600:[k2gget: downgrade] in 10.2 |
| * |
IIII |
5605370 |
10.2.0.4, 11.1.0.6 |
Various dumps / instance crash possible |
|
IIII |
5508574 |
10.2.0.4, 11.1.0.6 |
OERI[504] / OERI[99999] / Dump [kgscdump] with > 31 CPUs |
|
IIII |
5497611 |
10.2.0.4, 11.1.0.6 |
OERI[qctVCO:csform] from Xquery using XMLType constructor |
| PI |
IIII |
5496862 |
10.2.0.3, 11.1.0.6 |
AIX: Mandatory patch to use Oracle with IBM Technology Level 5 (5300-5) |
|
IIII |
4937225 |
10.2.0.3, 11.1.0.6 |
ORA-22 from OCIStmtExecute after OCISessionBegin |
|
IIII |
4483084 |
11.1.0.6 |
ORA-600 [LibraryCacheNotEmptyOnClose] on shutdown |
|
IIII |
14076510 |
10.2.0.5.8 |
ORA-600 [ktrgcm_3] in 10.2.0.5.3 – 10.2.0.5.7 |
|
IIII |
7612454 |
10.2.0.5.4 |
More “direct path read” operations / OERI:kcblasm_1 |
|
IIII |
7706062 |
10.2.0.5 |
OERI [17087] following concurrent hard parses on same cursor |
| * |
IIII |
7190270 |
10.2.0.4.1, 10.2.0.5 |
Various ORA-600 errors / dictionary inconsistency from CTAS / DROP |
|
IIII |
6852598 |
10.2.0.4.4, 10.2.0.5 |
Dump / corrupt library cache lock free list |
|
IIII |
4518443 |
10.2.0.3 |
Listener hang under load |
| + |
IIII |
7038750 |
10.2.0.4.1, 10.2.0.5 |
Dump (ksuklms) / instance crash |
|
IIII |
8575528 |
|
Missing entries in V$MUTEX_SLEEP.location |
|
IIII |
4359111 |
9.2.0.8, 10.1.0.5, 10.2.0.2 |
OERI [17281][1001] can occur on session switch in UPI mode |
|
IIII |
5671074 |
|
ORA-4052/ORA-3106 on create / refresh of materialized view |